

Scoring Open Source Contributors in the Age of AI Slop
Finding Good Eggs

The Problem
In December 2025, a GitHub community discussion titled “Ability to disable pull requests” went from niche feature request to rallying cry. Maintainers of azure-sdk, nixpkgs, homebrew-cask, and dozens of other projects described a new burden: waves of pull requests that looked plausible at first glance but fell apart under review. Hallucinated APIs, test suites that passed only because the tests themselves were rewritten. An Azure Core maintainer put it plainly: “The review trust model is broken.”
AI coding agents had crossed from demo to commodity. Generating a pull request against a popular project now takes seconds. Jeff Geerling, who maintains more than 300 Ansible projects, documented the flood and compared it to the crypto bubble: the cost of entry collapsed, but the cost of evaluation didn’t. Daniel Stenberg killed curl’s bug bounty after the confirmation rate collapsed from roughly one in seven to fewer than one in twenty.
These same tools have also made legitimate contributors more productive. Not every AI-assisted PR is junk, and lower barriers to entry bring in people who have real contributions to make. The problem is that review cost didn’t scale down with submission cost.
The pattern is consistent across ecosystems. In our own research across dozens of major AI/ML repositories, acceptance rates dropped while AI-related PR mentions surged. A maintainer who used to receive five PRs a week now receives thirty. Even if the same five good ones are in there, finding them takes six times longer.
Most of the low-quality contributions aren’t malicious, just shallow. A fix that works for the exact case in the bug report but breaks the invariant it was supposed to maintain. A refactoring that applies a pattern from one codebase without understanding why the target does things differently. Code that passes the test suite because the tests don’t cover the edge cases the maintainer knows about. Plenty of AI-assisted PRs are solid work, but maintainers can’t tell which are which without spending the same review time on each one. The traditional open-source on-ramp (start small, build trust, take on more) depends on maintainers being willing to look at contributions from unknowns. When the cost of looking goes up enough, that on-ramp closes. That’s the AI slop problem.
Maintainers already have an informal version of the solution. When they see a PR from an unfamiliar name, they click the profile, scan the contribution graph, check whether this person has contributed to projects they recognize. Good Egg automates that process by mining the contribution graph already in the GitHub API. Every data point is a decision a human maintainer already made (merge or reject). The tool aggregates those existing judgments into a structured score rather than making its own content-level evaluation. It doesn’t try to detect AI usage or flag tool choice. It looks at track record, which is tool-agnostic: a developer who uses AI tools effectively and gets PRs merged builds the same score as one who doesn’t. It answers one narrow question: is this person an established open-source contributor?
How Good Egg Works
Good Egg builds a weighted contribution graph from a user’s merged PRs and computes a trust score relative to a specific repository. Fetch data, build a graph, run a ranking algorithm, classify the result.
Data Collection
Via the GitHub GraphQL API, Good Egg fetches a user’s merged pull requests (up to 500) and metadata for each repository they’ve contributed to (star count, primary language, fork status, archived status). This typically takes 2-4 API calls per user.
Building the Graph
The core data structure is a bipartite directed graph. User nodes (user:{login}) connect to repository nodes (repo:{owner/name}) via weighted edges created by merged PRs. Reverse edges from repo to user at 0.3x the forward weight complete the graph. The graph for a typical contributor has 10-30 repository nodes. José Valim’s has over 90.
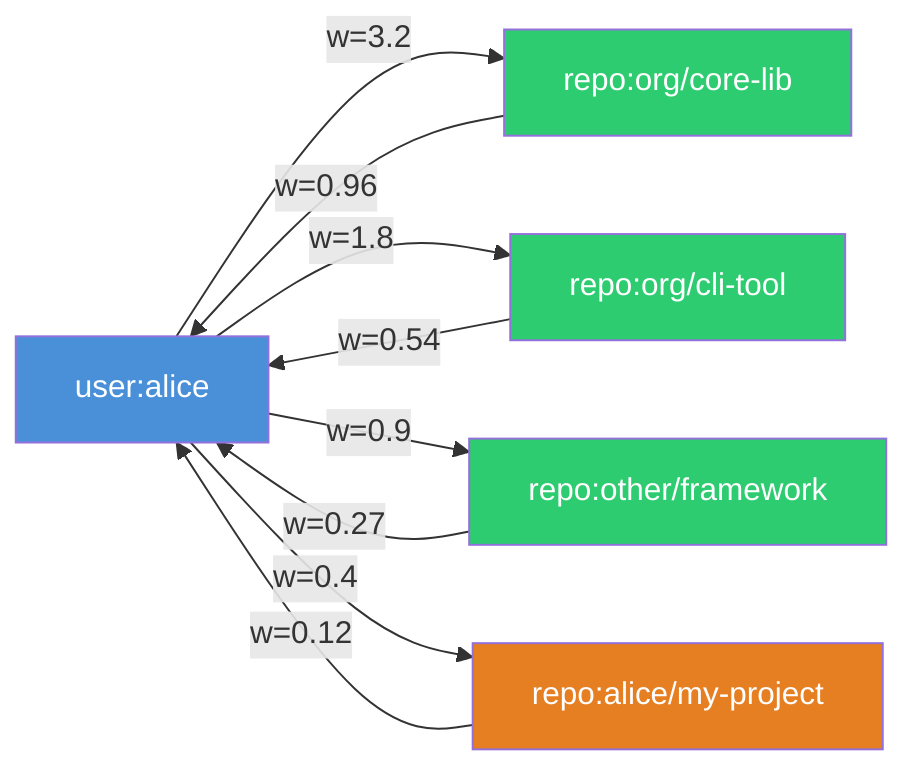
Each edge weight is recency_decay x repo_quality x edge_type_weight.
Recency decay uses a 180-day half-life. The formula is exp(-0.693 x days_ago / 180). Contributions older than 730 days are excluded entirely.
Repo quality is log1p(stars x language_multiplier), with penalties for archived repos (0.5x) and forks (0.3x). Star counts are normalized across ecosystems using a 28-language multiplier table ranging from 1.0x (JavaScript) to 5.96x (Nim), since a 1,000-star Rust library represents very different adoption than a 1,000-star JavaScript package. (v2 drops the language multiplier and uses raw star counts directly.)
Context-Specific Scoring
Scores depend on the target repository. A Python developer contributing to a Python project should score differently than the same developer contributing to a Rust project, which is why a Vercel founder can score MEDIUM against his own company’s repo (more on that below). The personalization vector biases the graph walk toward the context repo:
Anti-Gaming
PRs to your own repos are penalized at 0.3x (v1). No more than 20 PRs per repo are counted. Recency decay prevents old contribution padding from persisting. Low-star repos contribute less via the logarithmic quality curve. Forks don’t inherit the original’s star count.
A determined attacker could game the system by making real small contributions to established repos over time. But at that point, the gaming strategy closely resembles actually contributing to open source.
From Graph to Trust Level
Once the graph is constructed, scoring is straightforward. The graph is processed using personalized graph scoring (damping factor 0.85). The raw score is normalized to 0-1 via ratio / (ratio + 1) where ratio = raw_score * num_nodes.
Validating the Model
We ran a study on 5,129 pull requests across 49 repositories, each labeled merged or closed. Beyond the graph score, we tested additional features including merge rate and account age. We used logistic regression with likelihood ratio tests to determine which features carry real signal.
What Survived
The v1 trust score achieved an AUC of 0.647 as a standalone predictor. Moderate, but appropriate. A score with AUC 0.95 would mean code review is a formality.
Two features carried additional signal beyond the graph. Merge rate (the fraction of a user’s PRs that get merged) was highly significant (LRT p < 10^-12). Account age also contributed (LRT p = 1.2 x 10^-5).
What Didn’t
Four features were investigated and dropped:
Self-contribution penalty: the explicit 0.3x weight on PRs to your own repos didn’t improve discriminative power. Self-contributions to low-star personal repos already score low through the quality function, making the additional penalty redundant.
Language multipliers shift absolute quality scores but don’t improve relative ranking between contributors.
Diversity/volume adjustment: the graph handles prolific contributors naturally through its own topology.
Text dissimilarity was the most interesting failure. Higher PR-README similarity actually correlated with lower merge probability. We think low-effort PRs parrot project language, while experienced contributors write more targeted descriptions. Excluded until better understood.
Better Egg (v2)
Better Egg strips the three inert features from the graph (self-penalty, language multipliers, diversity/volume adjustment) and adds two new features via logistic regression.
Merge rate, computed as merged / (merged + closed), corrects survivorship bias. The v1 model only fetches merged PRs, so a user with 10 merged and 90 closed looks identical to one with 10 merged and 0 closed.
The other addition is account age, log-transformed as log(account_age_days + 1). A decade-old account with two merged PRs tells you something different from one created yesterday with the same count.
The combined model:
p = sigmoid(-0.8094 + 1.9138 * graph_score - 0.7783 * merge_rate + 0.1493 * log_account_age)
The graph score dominates (weight 1.9138). Account age is a gentle positive (0.1493).
The Negative Merge Rate Weight
The coefficient on merge rate is -0.7783. This doesn’t mean a high merge rate is bad. Each coefficient is conditional on the other features.
The graph score already captures contribution success. Users who contribute broadly across many repos tend to attempt more ambitious cross-project PRs with naturally lower merge rates. Given an already-high graph score, a very high merge rate is slight evidence of narrower contribution scope. The negative weight corrects for this conditional relationship.
Same AUC, Different Information
The AUC is identical. We shipped v2 anyway because merge rate corrects survivorship bias (two structurally different contributors who look identical to v1 become distinguishable) and account age stabilizes scores when the graph has few edges. Both carry statistically confirmed information. The flat AUC reflects that graph structure already captures most ranking signal in the validation dataset.
Scores in the Wild
We scored language creators, regular maintainers, corporate newcomers, and brand-new accounts.
The Full Spectrum
At the top, José Valim and tshepang land above 0.95. At the bottom, mstankov-amd’s four merged PRs across 2 repos earn a 0.58 MEDIUM. The interesting middle ground is vmoens: 500 merged PRs, but concentrated in just 6 repos, almost entirely within PyTorch. He lands at 0.76. High volume in a narrow set of repos produces a weaker graph than the same volume spread across many projects.
navalprakhar shows what LOW looks like: 6 merged PRs across 2 repos, but all to zero-star repos in a single small organization. The contributions exist but carry no ecosystem weight, so the graph score is 0.0. v2 lifts this to 0.42 MEDIUM using the account’s 86% merge rate and 6-year age.
Known bots like dependabot are caught by login-pattern detection and short-circuited to BOT. Accounts with no merged PRs score 0.00 UNKNOWN regardless of age. A brand-new account created today looks the same; UNKNOWN means no data.
Interesting Cases
Guillermo Rauch co-founded Vercel, created Socket.io, and is one of the most recognized names in JavaScript. He also has zero merged PRs in vercel/next.js (his 144 merged PRs span 53 other repos). His top contribution by volume is to his own blog (33 PRs). When scored against Next.js, the graph finds no direct connection, producing a graph score of 0.56 and a v1 trust level of MEDIUM.
Rauch has transitioned from building to leading, and the graph reflects that. In v2, his 17.7-year account and 78% merge rate push the composite score to 0.73, clearing the HIGH threshold. Merge rate and account age earn their place here.
José Valim is the opposite end. The Elixir creator has the highest graph score (0.98) and his match and non-match scores are effectively identical. His contribution graph (500 PRs across 93 repos including Elixir, Phoenix, Livebook, Erlang/OTP) is so densely connected that the choice of context repo makes no measurable difference.
vmoens is informative because he’s not famous. His contributions cluster around TorchRL and tensordict, so despite 500 merged PRs his v1 score of 0.76 is HIGH, but barely.
mstankov-amd has four merged PRs across 2 repos and a 356-day account. The v1 score (0.58) is MEDIUM, with limited but real history. In v2, this rises to 0.66 as account age adds a small boost.
v1 vs v2 Comparison
v2 compresses the score range. v1 spans 0.00 to 0.98 across this set; v2’s occupied range is roughly 0.66 to 0.86 for contributors with data. High v1 scorers drop slightly as the merge rate component moderates extreme graph scores. Low v1 scorers rise as account age and merge rate provide additional signal. We think the tradeoff is right for most use cases, but maintainers who want maximum resolution at the top of the scale may prefer v1.
Limitations and What’s Next
Cold Start and Gaming
A talented developer making their first contribution will score LOW. The tool measures established contribution history, not potential. A skilled developer using AI tools well will build a track record the same way anyone else does, and their score will reflect that over time. A LOW score should trigger closer review. Use it for triage, not gatekeeping.
On the adversarial side, the layered defenses make gaming expensive enough that the easiest path is genuine contribution. A determined attacker making real small contributions over months could still build a score.
Data Limitations
The scoring graph is built from the most recent 500 merged PRs, so extremely prolific contributors have truncated histories. The 180-day half-life means a contributor who was very active three years ago but has since stopped will score lower than their history would suggest. Usually correct for triage purposes.
Other Approaches
Mitchell Hashimoto’s Vouch uses explicit referrals from trusted contributors, which captures high-signal human judgment but requires active participation and doesn’t help with cold-start. The two tools are complementary.
Future Directions
Better new-contributor detection is the highest priority. Account age helps, but richer signals exist in pre-PR activity patterns, issue engagement, and profile metadata.
The inverted text-similarity finding from the validation study deserves deeper investigation. More sophisticated text analysis might extract a real signal from what turned out to be a confound at the bag-of-words level.
We’re also looking at time-series patterns like contribution velocity and burst vs. steady activity. Graph-based project relatedness could replace crude language matching with shared-contributor signals. And cross-platform data from GitLab and other forges would give a more complete picture.
We published the failures alongside the successes. The code is open source, the methodology is documented, and the scores are auditable. The goal is to help maintainers stay open to contributions, including AI-assisted ones, by giving them a fast signal to triage against instead of shutting the door entirely. Try it below.
Appendix: Try It Yourself
Good Egg is open source (MIT). The fastest way to try it requires no installation, just uv:
# Score a contributor with the v1 (default) model
GITHUB_TOKEN=ghp_... uvx good-egg score <username> --repo <owner/repo>
# Score with the v2 (Better Egg) model
GITHUB_TOKEN=ghp_... uvx good-egg score <username> --repo <owner/repo> --scoring-model v2
Good Egg also runs as a GitHub Action, a Python library, and an MCP server for AI assistant integration.
Source: github.com/2ndSetAI/good-egg | Methodology | Configuration